HTTP 是什么
HyperText Transfer Protocol, 超文本传输协议
超文本传输协议
超文本
- “超文本”,就是“超越了普通文本的文本”,包含文字、图片、音频和视频等的混合体
- 最关键的是含有“超链接”,能够从一个“超文本”跳跃到另一个“超文本”,形成复杂的非线性、网状的结构关系。
传输
- 是一个“双向协议”
- 数据虽然是在 A 和 B 之间传输,但并没有限制只有 A 和 B 这两个角色,允许中间有“中转”或者“接力”
HTTP 是一个在计算机世界里专门用来在两点之间传输数据的约定和规范。
协议
- 两个或多个参与者
- 是对参与者的一种行为约定和规范
HTTP 是一个用在计算机世界里的协议。它使用计算机能够理解的语言确立了一种计算机之间交流通信的规范,以及相关的各种控制和错误处理方式。
总结下来 具体说
HTTP 是一个在计算机世界里专门在两点之间传输文字、图片、音频、视频等超文本数据的约定和规范.
HTTP 不是什么
HTTP 不是互联网
HTTP 是构建互联网的一块重要拼图,而且是占比最大的那一块。但是构建互联网还包含其他,超文本资源使用 HTTP,普通文件使用 FTP,电子邮件使用 SMTP 和 POP3 等。
使用浏览器访问的 是万维网(www),只是互联网的一部分
HTTP 不是编程语言
编程语言是人与计算机沟通交流所使用的语言,而HTTP 是计算机与计算机沟通交流的语言,是要通过 编程语言实现 http 进行与其他计算机通信的。
HTTP 和 HTML 不可混为一谈
HTML 是超文本的载体,是一种标记语言,使用各种标签描述文字、图片、超链接等资源,并且可以嵌入 CSS、JavaScript 等技术实现复杂的动态效果。虽然通常,我们使用 http 传输 html 但是,http 还可以传输其他文本、文件。
HTTP 不是一个孤立的协议
- HTTP 通常跑在 TCP/IP 协议栈之上:依靠 IP 协议实现寻址和路由、TCP 协议实现可靠数据传输、DNS 协议实现域名查找、SSL/TLS 协议实现安全通信。
- 还有一些协议依赖于 HTTP,例如 WebSocket、HTTPDNS 等。这些协议相互交织,构成了一个协议网,而 HTTP 则处于中心地位。
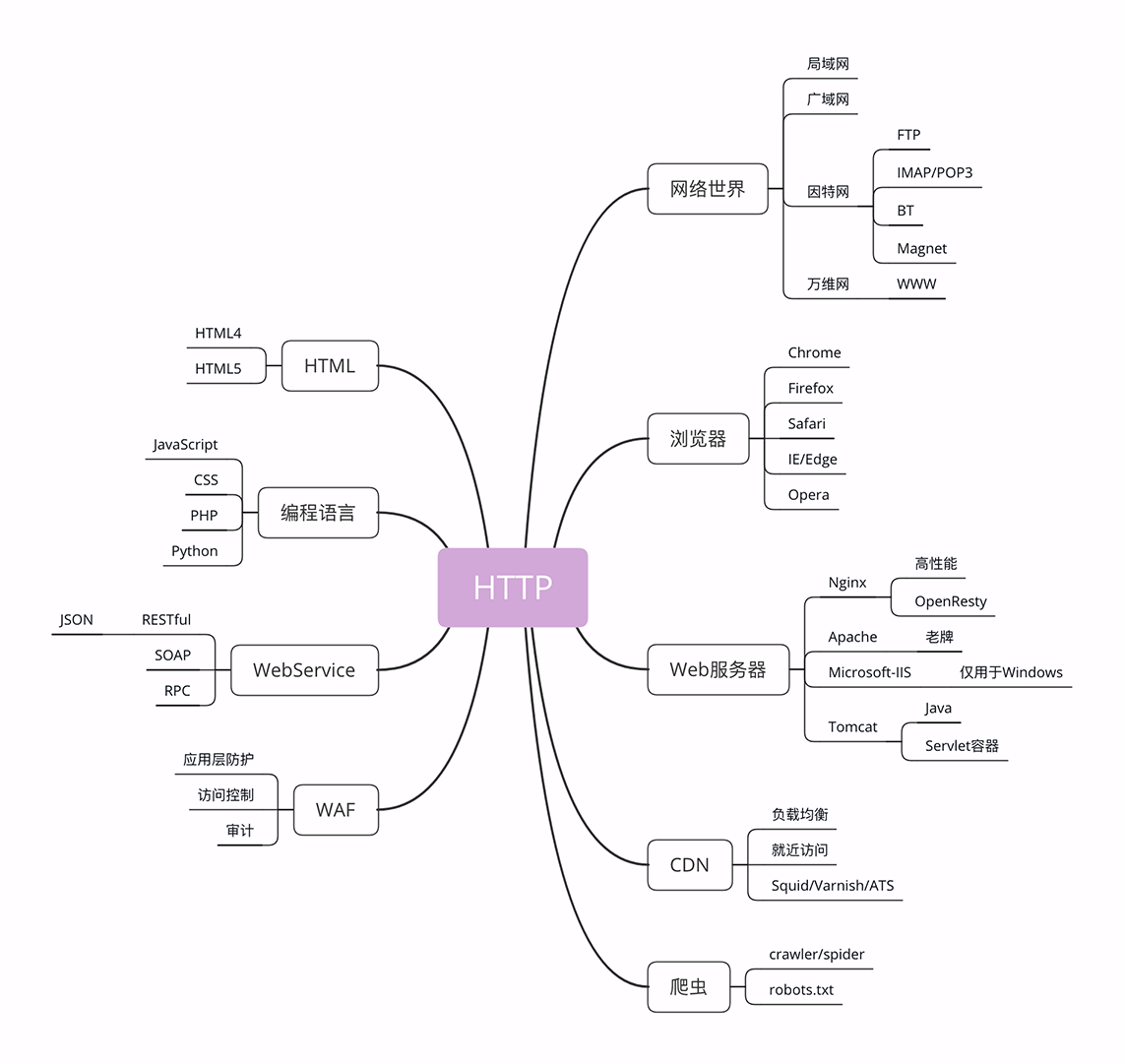
与 HTTP 相关的各种概念
互联网的正式名称是 Internet,里面存储着无穷无尽的信息资源,我们通常所说的“上网”实际上访问的只是互联网的一个子集“万维网”(World Wide Web),它基于 HTTP 协议,传输 HTML 等超文本资源,能力也就被限制在 HTTP 协议之内。
互联网上还有许多万维网之外的资源,例如常用的电子邮件、BT 和 Magnet 点对点下载、FTP 文件下载、SSH 安全登录、各种即时通信服务等等,它们需要用各自的专有协议来访问。
浏览器
浏览器的正式名字叫“Web Browser”,顾名思义,就是检索、查看互联网上网页资源的应用程序,名字里的 Web,实际上指的就是“World Wide Web”,也就是万维网。浏览器本质上是一个 HTTP 协议中的请求方,使用 HTTP 协议获取网络上的各种资源。
在 HTTP 协议里,浏览器的角色被称为“User Agent”即“用户代理”,意思是作为访问者的“代理”来发起 HTTP 请求。不过在不引起混淆的情况下,我们通常都简单地称之为“客户端”。
Web 服务器
服务器,Web Server。服务器是一个很大也很重要的概念,它是 HTTP 协议里响应请求的主体,通常也把控着绝大多数的网络资源,在网络世界里处于强势地位。
硬件含义就是物理形式或“云”形式的机器,在大多数情况下它可能不是一台服务器,而是利用反向代理、负载均衡等技术组成的庞大集群。
软件提供 Web 服务的应用程序,通常会运行在硬件含义的服务器上。它利用强大的硬件能力响应海量的客户端 HTTP 请求,处理磁盘上的网页、图片等静态文件,或者把请求转发给后面的 Tomcat、Node.js 等业务应用,返回动态的信息
- Apache 是老牌的服务器,到今天已经快 25 年了,功能相当完善,相关的资料很多,学习门槛低,是许多创业者建站的入门产品。
- Nginx 是 Web 服务器里的后起之秀,特点是高性能、高稳定,且易于扩展。在高流量的网站里更是不二之选。
- 此外,还有 Windows 上的 IIS、Java 的 Jetty/Tomcat 等,因为性能不是很高,所以在互联网上应用得较少。
CDN [ 负载均衡,就近访问 ]
CDN,全称是“Content Delivery Network”,翻译过来就是“内容分发网络”。它应用了 HTTP 协议里的缓存和代理技术,代替源站响应客户端的请求。它可以缓存源站的数据,让浏览器的请求不用“千里迢迢”地到达源站服务器,直接在“半路”就可以获取响应。如果 CDN 的调度算法很优秀,更可以找到离用户最近的节点,大幅度缩短响应时间。
CDN 也是现在互联网中的一项重要基础设施,除了基本的网络加速外,还提供负载均衡、安全防护、边缘计算、跨运营商网络等功能,能够成倍地“放大”源站服务器的服务能力
爬虫
是一种可以自动访问 Web 资源的应用程序。它们就像是一只只不知疲倦的、辛勤的蚂蚁,在无边无际的网络上爬来爬去,不停地在网站间奔走,搜集抓取各种信息,故而 成为爬虫。
绝大多数是由各大搜索引擎“放”出来的,抓取网页存入庞大的数据库,再建立关键字索引,这样我们才能够在搜索引擎中快速地搜索到互联网角落里的页面。
爬虫也有不好的一面,它会过度消耗网络资源,占用服务器和带宽,影响网站对真实数据的分析,甚至导致敏感信息泄漏。所以,又出现了“反爬虫”技术,通过各种手段来限制爬虫。其中一项就是“君子协定”robots.txt,约定哪些该爬,哪些不该爬。
无论是“爬虫”还是“反爬虫”,用到的基本技术都是两个,一个是 HTTP,另一个就是 HTML
图形验证码等,也是一种反爬虫手段。
linux 上的 wget、curl 等命令行工具也是基于 http,也是一种 user agent