最早,在一家做安防类的公司,使用海康威视等摄像头 提供的 视频流【 rtsp, rtmp 协议的 h264 视频流 】 在 浏览器客户端播放。
- 在当时,只能使用的几种方式:
- 直接在借助 第三方浏览器插件 在浏览器播放。VLC 等第三方浏览器插件 提供的api 【 缺点: 需要 客户提前安装 插件,只有vlc 插件可以播放 rtsp的视频流 ,而已只在ie 已经过时 】
- 服务端转码 成为 web 直接可以播放的 hls(m3u8) [ 缺点 :需要服务器和更多带宽 成本较高,而且 实时性较差 ]
- 在当时,只能使用的几种方式:
参与云手机的研发【 web网页上 控制远端安卓手机 (触控层 + 视频层),安卓端 发送视频流,web 端进行解码播放 】
- 早期 解码方案 使用 第三方库 ws-avc-playerjs【 基于Broadway/Player解码 ( Webassembly + FFmpeg 视频解码 + canvas ) 】ws-avc-playerjs 虽然 不支持音频,没有使用流协议进行压缩传输,播放及其容易卡顿,但是其提供的 解决思路,确实值得深入学习。
- 借助 webrtc 解决方案,绕开 自己直接进行解码,音视频同步等一些列繁杂工作
蓝将云手机是什么
通过 web网页 控制远端安卓手机,实现广告中 软件、游戏的体验功能;游戏工作室 挂机代练等等使用场景。
蓝将网址
如何实现的
前端分为 视频层 和 触控层
- 视频层 接收 远端安卓手机 视频流进行播放
- 触控层 点击后通过 websocket 给安卓端 发送 事件消息
本文 仅以 介绍视频播放 方向内容
实现都经历了哪些过程
最早方案:使用 第三方库 ws-avc-playerjs【 基于Broadway/Player解码 ( Webassembly + FFmpeg 视频解码 + canvas ) 】
面临的问题:
- 没有 音频 【 需求硬性要求 】
- 播放时常 存在 延迟卡顿、累计延迟【 手机等内存设备更为明显 】
要解决上面问题,还得从头捋,了解 音视频基本知识 ,如何和完成视频播放。
音频
声音本质就是能量波,为了将模拟信号数字化 分别要对模拟信号进行 采样、量化和编码。
- 采样
- 采样就是 在时间轴上对信号进行数字化。
- 根据奈奎斯特定理(也称为采样定理),按比声音最高频率高 2 倍以上的频率对声音进行采样(也称为 AD 转换),
- 对于高质量的音频信号,其频率范围(人耳 能够听到的频率范围)是 20Hz~20kHz,所以采样频率一般为 44.1kHz,这样就可以保证采样声音达到 20kHz 也能被数字化,从而使得 经过数字化处理之后,人耳听到的声音质量不会被降低。
- 而所谓的 44.1kHz 就是代表 1 秒会采样 44100 次。
量化
量化是指在幅度轴上对信号进行数字化,比如用 16 比特(16 个二进制位) 的二进制信号来表示声音的一个采样,而 16 比特(一个 short)所表示的 范围是[-32768,32767],共有 65536 个可能取值,因此最终模拟的音频 信号在幅度上也分为了 65536 层编码
所谓编码,就是按照一定的格式记录采样和量化后的数字数据,比如顺序存储或压缩存储,等等。
音频编码
上文中,提到了 CD 音质的数据采样格式,曾计算出每分钟需要的存 储空间约为 10.1MB,如果仅仅是将其存放在存储设备(光盘、硬盘) 中,可能是可以接受的,但是若要在网络中实时在线传播的话,那么这 个数据量可能就太大了,所以必须对其进行压缩编码。
压缩编码
- 压缩编码的基本指标之一就是压缩比,压缩比通常小于 1(否则就没有必要去做压缩, 因为压缩就是要减小数据容量)
- 压缩编码的原理实际上是压缩掉冗余信号,冗余信号是指不能被人 耳感知到的信号,包含人耳听觉范围之外的音频信号以及被掩蔽掉的音频信号等。
压缩算法:
- 无损压缩:无损压缩是指解压后的数据可以完全复原。
- 有损压缩:指解压后的数据不能完全复原,会丢失一部分信息;
- 用得较多;
- 压缩比越小,丢失的信息就越多,信号还原后的失真就会 越大;
- 根据不同的应用场景(包括存储设备、传输网络环境、播放设备 等),可以选用不同的压缩编码算法,如 PCM、WAV、AAC、MP3、 Ogg 等
PCM
PCM 是软件层接收到最原始的音频格式数据。浏览器支持 audio api 直接播放 PCM
PCM(Pulse Code Modulation,脉冲编码调制) 音频数据是未经压缩的音频采样数据裸流,它是由模拟信号经过采样、量化、编码转换成的标准数字音频数据。
通常所说的音频的裸数据格式就是 PCM数据。描述一段 PCM 数据一 般需要以下几个概念: 量化格式(sampleFormat)、采样率 (sampleRate)、声道数(channel)。
以 CD 的音质为例:
- 量化格式为 16-bit(2 字节),采样率(Sample Rate)为 44100,声道数为 2,这些信息就描述了 CD 的音质。
- 而对于声音格式,还有一个概念用来 描述它的大小,称为数据比特率(即 1 秒时间内的比特数目,用于衡量 音频数据 单位时间内的容量大小)
对于 CD 音质的数据,比特率为:44100 * 16 * 2 = 1378.125kbps
1 分钟里,这类 CD 音质的数据需要占据多大的存储需要 1378.125 * 60 / 8(8位是1字节得到KB) / 1024(KB换算MB) = 10.09MB
如果 量化格式(sampleFormat) 更加精确【 比如用 4 字节(32-bit)来描述一个采样】,或者 采样率(sampleRate) 更加密集(比如 48kHz 的采样率),那么所占的 存储空间就会更大,同时能够描述的声音细节就会越精确。
存储的这段二进制数据即表示将模拟信号转换为数字信号了,以后就可以对这段二进制数据进行存储、播放、复制,或者进行其他任何操作。
图像
视频是由一幅幅图像组成的,所以要学习视频还得从图像说起
RGB 表示方式:
- 浮点表示:取值范围为 0.0 ~ 1.0,比如,在 OpenGL ES 中对每一个子像素点的表示使用的就是这种表达方式。
- 整数表示:取值范围为0 ~ 255或者00 ~ FF,8 个比特表示一个子像素,32 个比特(除了 RGB 三色外,还有 alpha 透明度;也就是 4*8)表示一个像素,这就是类似于某些平台上表示图像格式的 RGBA_8888 数据格式。
对于一幅图像,一般使用整数表示方法来进行描述, 比如计算一张 1280×720 的 RGBA_8888 图像的大小,可采用如下方式:1280 * 720 * 4 = 3.516MB 这也是位图(bitmap)在内存中所占用的大小,所以每一张图像的裸数据都是很大的。
对于图像的裸数据来讲,直接在网络上进行传输也是不太可能的,所以就有了图像的压缩格式, 比如 JPEG 压缩:JPEG 是静态图像压缩标准,由 ISO 制定。
JPEG 图像压缩算法在提供良好的压缩性能的同时,具有较好的重建质量。 这种算法被广泛应用于图像处理领域,当然其也是一种有损压缩。 在很多网站如淘宝上使用的都是这种压缩之后的图片,但是,这种压缩不能直接应用于视频压缩,因为对于视频来讲,还有一个时域上的因素需要考虑,也就是说,不仅仅要考虑帧内编码,还要考虑帧间编码。视频采用的是更成熟的算法。
YUV 表示方式【 主流 】
- YUV 也是一种色彩编码方法,主要用于电视系统以及模拟视频领域。它将亮度信息(Y)与色彩信息(UV)分离,即使没有 UV 信息一样可以显示完整的图像,只不过是黑白的,这样的设计很好地解决了彩色电视机与黑白电视的兼容问题。
- 与 RGB 视频信号传输相比,它最大的优点在于只需要占用极少的频宽(RGB 要求三个独立的视频信号同时传输)。其中“Y”表示明亮度(Luminance 或 Luma),也称灰阶值;而“U”和“V”表示的则是色度(Chrominance 或 Chroma),它们的作用是描述影像的色彩及饱和度,用于指定像素的颜色。
- “亮度”是透过 RGB 输入信号来建立的,方法是将 RGB 信号的特定部分叠加到一起。“色度”则定义了颜色的两个方面——色调与饱和度,分别用 Cr 和 Cb 来表示。其中,Cr 反映了 RGB 输入信号红色部分与 RGB 信号亮度值之间的差异,而 Cb 反映的则是 RGB 输入信号蓝色部分与 RGB 信号亮度值之间的差异。
视频
视频编码
- 音频压缩主要是去除冗余信息,从而实现数据量的压缩。其实视频压缩也是通过去除冗余信息来进行压缩的。
- 相较于音频数据,视频数据有极强的相关性,也就是说有大量的冗余信息,包括空间上的冗余信息和时间上的冗余信息。使用帧间编码技术可以去除时间上的冗余信息,具体包括以下几个部分。
- 运动补偿:运动补偿是通过先前的局部图像来预测、补偿当前的局部图像,它是减少帧序列冗余信息的有效方法。
- 运动表示:不同区域的图像需要使用不同的运动矢量来描述运动信息。
- 运动估计:运动估计是从视频序列中抽取运动信息的一整套技术。使用帧内编码技术可以去除空间上的冗余信息。
ISO 视频压缩标准(Motion JPEG 即 MPEG):
- Mpeg1(用于 VCD)
- Mpeg2(用于 DVD)
- Mpeg4 AVC(现在流媒体使用最多的就是它了)
- ITU-视频压缩标准
- H.261
- H.262
- H.263
- H.264 (集中了以往标准的所有优点,并吸取了以往标准的经验)
- h.265
现在使用最多的就是 H.264 标准,H.264 创造了多参考帧、多块类型、整数变换、帧内预测等新的压缩技术,使用了更精细的分像素运动矢量(1/4、1/8)和新一代的环路滤波器,这使得压缩性能得到大大提高,系统也变得更加完善
编码概念:
IPB 帧
视频压缩中,每帧都代表着一幅静止的图像。而在进行实际压缩时,会采取各种算法以减少数据的容量,其中 IPB 帧就是最常见的一种。
- I 帧:关键帧。压缩率低,可以单独解码成一幅完整的图像。
- P 帧:参考帧。压缩率较高,解码时依赖于前面已解码的数据。
- P 帧需要参考其前面的一个 I 帧或者 P 帧来解码成一张完整的视频画面。
- B 帧:前后参考帧。压缩率最高,解码时不光依赖前面已经解码的帧,而且还依赖它后面的 P 帧。换句话说就是,B 帧后面的 P 帧要优先于它进行解码,然后才能将 B 帧解码。
- B 帧则需要参考其前一个I 帧或者 P 帧及其后面的一个P 帧来生成一张完整的视频画面,所以P 帧与 B 帧去掉的是视频帧在时间维度上的冗余信息
H.264 的 IDR 帧与 I 帧的理解
- IDR 帧(instantaneous decoding refreshpicture) IDR 帧与 I 帧的区别
- IDR 帧就是一种特殊的 I 帧,即这一帧之后的所有参考帧只会参考到这个 IDR 帧,而不会再参考前面的帧。在解码器中,一旦收到一个 IDR 帧,就会立即清理参考帧缓冲区,并将 IDR 帧作为被参考的帧。
因为 H.264 采用了多帧预测,所以 I 帧 之后的 P 帧有可能会参考 I 帧之前的帧,这就使得在随机访问的时候不能以找到 I 帧作为参考条件,因为即使找到 I 帧,I 帧之后的帧还是有可能解析不出来
I 帧、P 帧、B 帧 的说明(编码器工作):
- 帧率 25fps( 指每秒 25 个 P 帧或 B 帧)
- 视频画面变化不大情况下, 每间隔 25 个参考帧 出 一个 I 帧
- 视频画面变化较大(如:电影场景切换)时,会立马 出一个 I 帧, 用于更换视频场景及后面的参考帧处理解码
视频播放器
视频协议
- 只有在有网络时通过浏览器或者移动端APP才能看到的视频。
- 常见的直播流协议有:RTMP、RTSP、HTTP 等;
- 常见的点播协议有:http-MP4、http-FLV、HLS 等。
- 在连接视频协议时,除了音视频频流和metadata之外,可能还会携带播放的信令
视频容器
- 通常说的视频的格式,比如 .mp4, .mov, .wmv, .m3u8, .flv 等等被称为 容器 【container】。
- 含了video数据、audio数据、metadata(用于检索视音频payload格式等信息)。
- 每个格式的封装格式不一样,比如FLV格式的基本单元是Tag,而MP4格式的基本单元是Box,辅助的 meta信息用于检索找到对应的原始数据。
编解码器
- Mpeg2, H.264, H.265等视频编码标准被称为 编解码器 ( codec)。
- 一个视频格式比如 mp4可以使用任何标准化的压缩算法,这些信息都会被包含在一个视频文件的meta信息中来告诉播放器该用什么编解码算法来播放。
所以通过以上只是,我们基本知道,一个视频播放器的 播放文件的几个步骤
播放本地文件则不需要解协议
- 解封装
- 解码视音频
- 视音频同步
播放一个互联网上的视频文件
- 解协议 [rtmp\rtsp\http-flv\hls]
- 解封装(容器) [mp4\ts\avi]
- 解码视音频
- 视音频同步

回到上面,分析 ws-avc-player 的解题思路是
核心思路:
通过websock 接收 arraybuffer,创建缓冲器
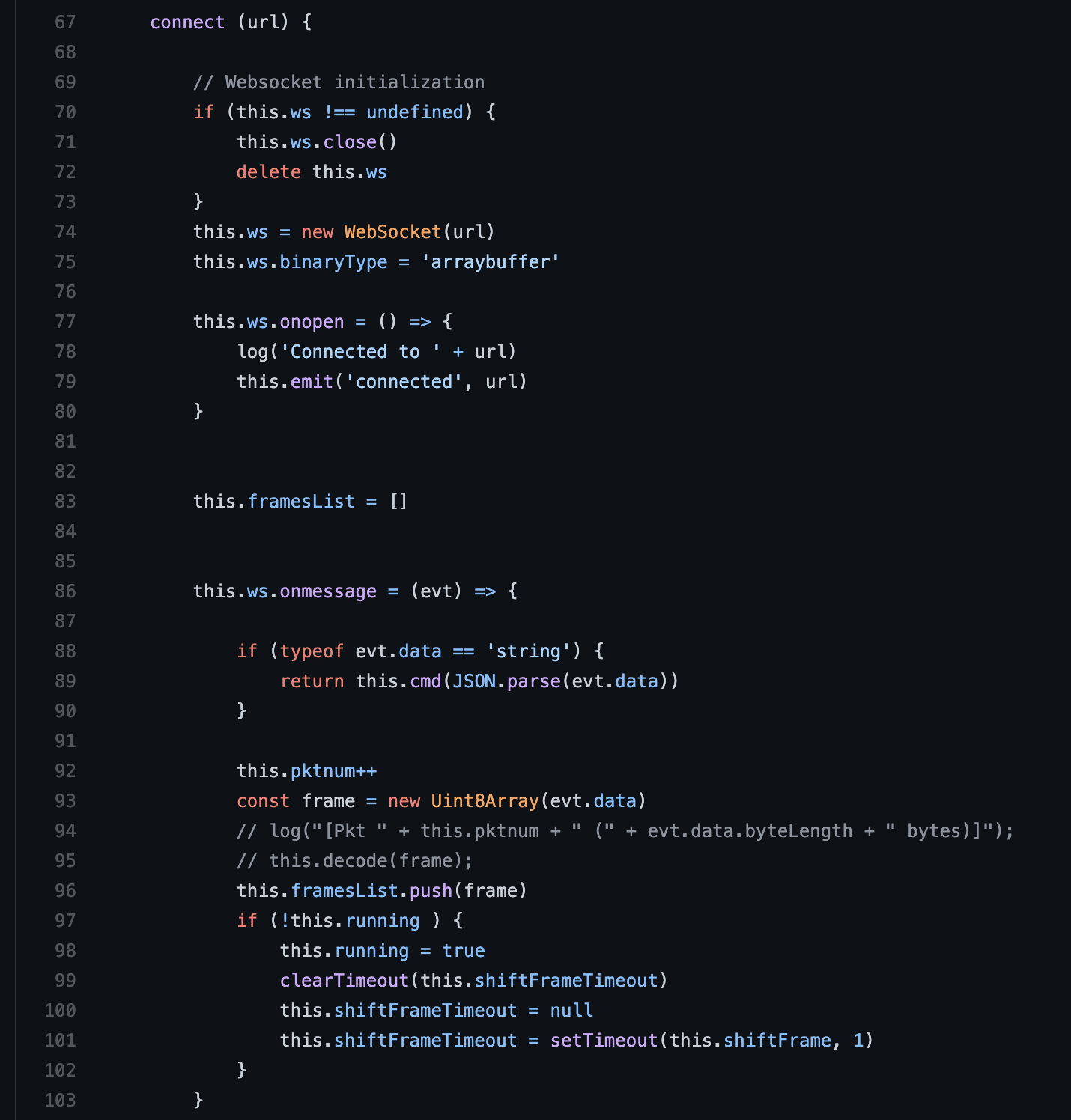
通过缓冲器 借助 浏览器api: requestAnimationFrame 一帧一帧 解码绘制
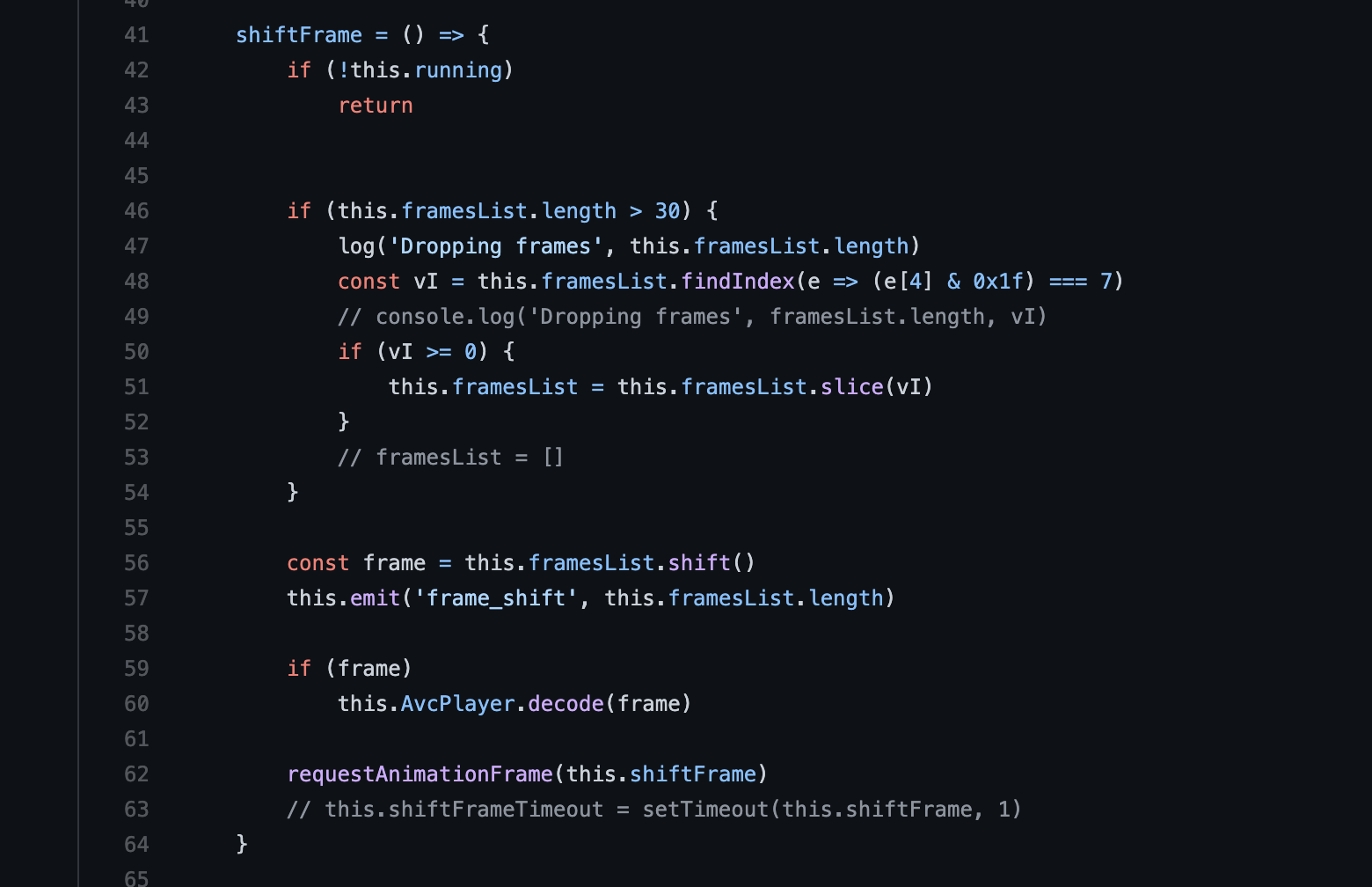
借助 Broadway/Player库( WebAssembly + FFmpeg )进行 视频解码
分析
没有使用 视频协议 导致 流量带宽 消耗大
在远端编码阶段没有 使用容器 包裹音频数据,且 接收端 没有 音频解码操作
增加音频可能需要单独的 websocket 接收 音频数据 进行解码 播放,而且还存在 音视频同步问题
tcp 的 传输方式 延迟 无法避免
团队研发能力不足,无法进行二次开发
综上,选择了放弃该方案。
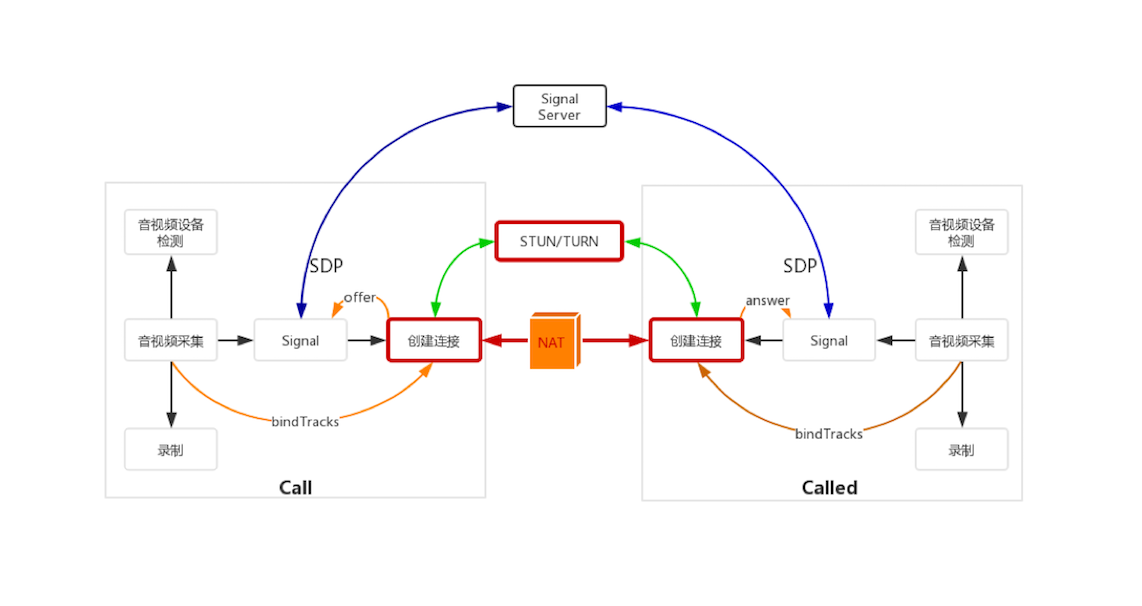
最终落地 使用 webrtc 全家桶
- 编码端 解码端 统一解决方案
- 低延迟(RTP/RTCP 基于udp)
- 自适应码率
- 稳定传输
仍然存在延迟,尚且需要优化。